wir haben seid einer Ram-Erweiterung bei einem ESX 5.5 das Problem von ständig auftretenden Purple Screens mit Systemabstürzen. Nach erstmaligem Auftreten wurde der Ramtausch wieder rückgängig gemacht, allerdings traten anschließend trotzem weiterhin Fehler auf.
Der ESX ist über ISCSI an ein externes Storage angebunden. Eingebaut ist ein LSI Controller.
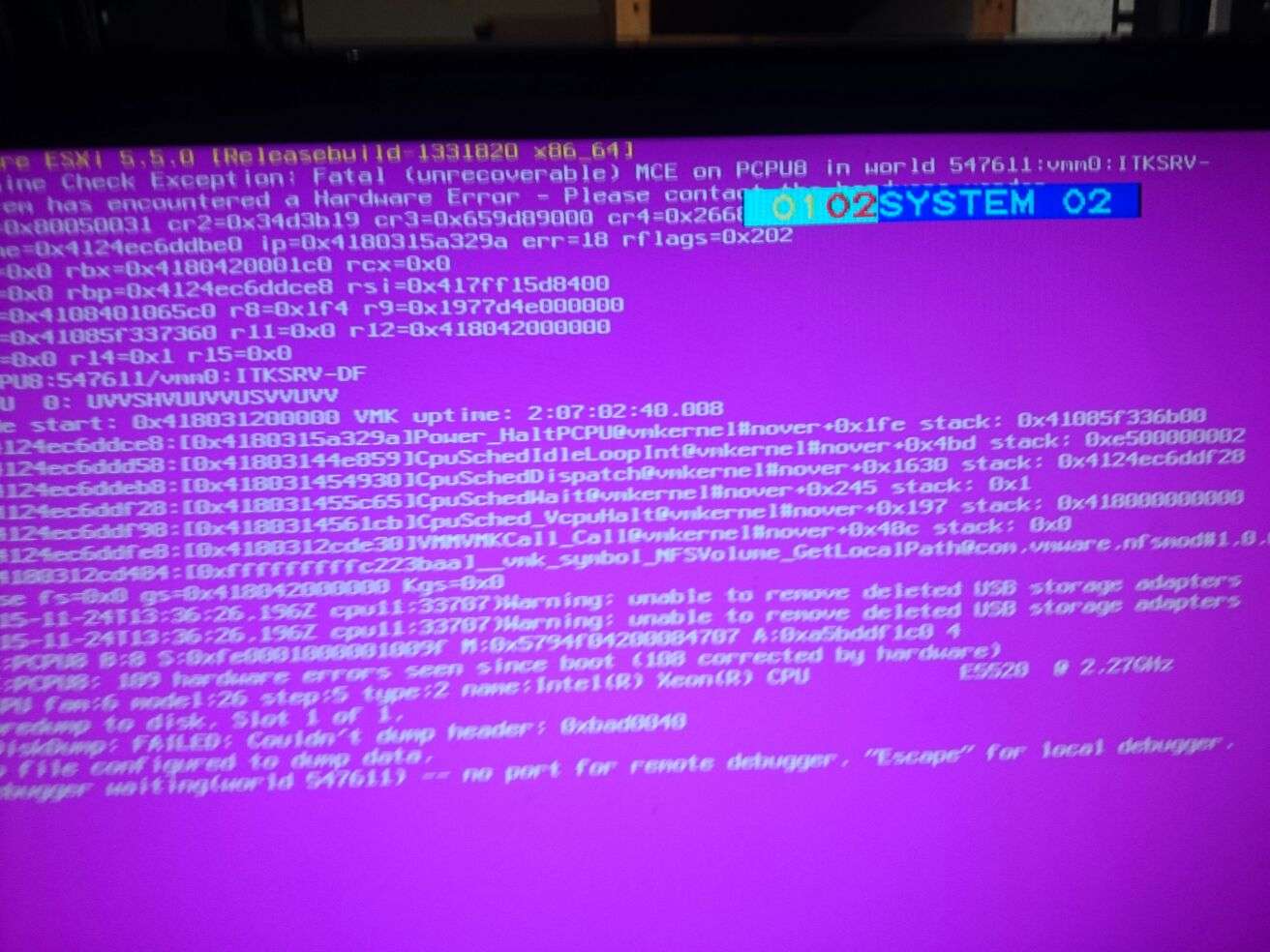
Unten ist ein Bild des Purple Screens.
Leider kann ich aus mir nicht ganz erklärlichen Gründen momentan keinen Screenshot des bildschirms hinzufügen..
Vielen Dank für jegliche hilfe hierbei!
Edit: Hier nun ein Link zum PSOD: http://imageshack.com/a/img905/2695/ydtHps.jpg
{kind=link}