Die Foren-SW läuft ohne erkennbare Probleme. Sollte doch etwas nicht funktionieren, bitte gerne hier jederzeit melden und wir kümmern uns zeitnah darum. Danke!
CBT Informationen ganz neu erstellen
CBT Informationen ganz neu erstellen
Hallo, ich habe ein kleines Problem und zwar möchte ich Vms vom ESX sichern leider sind die Platten von ein paar Vms sehr zugemüllt wurden von Backuptools, konkret habe ich nun die Situation das ich eine 500 gb vmdk habe von der 4 gb benutzt werden, durch die Backups innerhalb der vm bekomme ich bei einer Querychangedsektors wohl alle Sektoren zurück, ist ja logisch, hat sich alles geändert, gibt es nun eine Möglichkeit mit der ich dafür Sorgen kann das ich neue cbt files bekomme, indem der ESX einfach die Daten durchgeht und danach die cbts neu erstellt?
Eigentlich kann man die Dateien einfach loeschen...
Wenn ctk fuer die VM enabled ist, wird der ESXi beim naechsten Start der VM wieder damit anfangen, Vermerke fuer geaenderte Bloecke in eine neu erstellte Datei zu schreiben.
Um ganz sicher zu gehen, kannst Du ja diesem KB-Artikel folgen.
Ach ja:
Die 500GB-Datei bekommst Du damit selbstverstaendlich NICHT auf 4GB verkleinert.
Wenn ctk fuer die VM enabled ist, wird der ESXi beim naechsten Start der VM wieder damit anfangen, Vermerke fuer geaenderte Bloecke in eine neu erstellte Datei zu schreiben.
Um ganz sicher zu gehen, kannst Du ja diesem KB-Artikel folgen.
Ach ja:
Die 500GB-Datei bekommst Du damit selbstverstaendlich NICHT auf 4GB verkleinert.
mit den cbt hab ich schon soweit, da ich im moment meine Eigene Backup Lössung schreibe aber eben vor dem Problem stehe.
Das ich das ganze nicht auf Glat 4 gb bekomme ist mir klar, der Soap Request liefert auch gerne mal Blöcke mit die sich eigentlich garnicht geändert haben/Sektorweise Lesen von Blocks noch dazu, mir gehts aber darum in der cbt sowenig geänderte Blöcke wie möglich zu haben.
(Also ich will sie nicht verkleinern, ich möchte viel mehr die Wahren Changed Blocks)
Ich finde leider nirgendswo eine Information ob dieses An/Ausstelen das komplette File neu Einliest.
Ich könnte Backupen und dabei alle sektoren die effektiv kein Inhalt haben auslassen und dann einfach eine Neue Vm erstellen und vom Backup wieder einspielen, die damit erstellten cbts sollten Korrekt sein, würde diesen Weg aber ungern gehen wenn es andere Möglichkeiten gibt.
Das ich das ganze nicht auf Glat 4 gb bekomme ist mir klar, der Soap Request liefert auch gerne mal Blöcke mit die sich eigentlich garnicht geändert haben/Sektorweise Lesen von Blocks noch dazu, mir gehts aber darum in der cbt sowenig geänderte Blöcke wie möglich zu haben.
(Also ich will sie nicht verkleinern, ich möchte viel mehr die Wahren Changed Blocks)
Ich finde leider nirgendswo eine Information ob dieses An/Ausstelen das komplette File neu Einliest.
Ich könnte Backupen und dabei alle sektoren die effektiv kein Inhalt haben auslassen und dann einfach eine Neue Vm erstellen und vom Backup wieder einspielen, die damit erstellten cbts sollten Korrekt sein, würde diesen Weg aber ungern gehen wenn es andere Möglichkeiten gibt.
-
irix
- King of the Hill
- Beiträge: 13063
- Registriert: 02.08.2008, 15:06
- Wohnort: Hannover/Wuerzburg
- Kontaktdaten:
CBT nutzt eine Variable Groesse wobei wohl der Standard 64K sind. Dies sollte erklaeren warum man "mehr" Daten geliefert bekommt als sich Netto maessig im FS des OS geaendert haben.
vRanger hat ein Feature was sich ABM (Active Block Mapping) nennt und das befragt das NTFS um heraus zubekommen ob Daten im FS als geloescht markiert sind. Zusaetzlich haben vRanger und Veeam sowie wahrscheinlich andere die Moeglichkeit die Page/Swapfile vom Windows heraus zufiltern.
Gruss
Joerg
vRanger hat ein Feature was sich ABM (Active Block Mapping) nennt und das befragt das NTFS um heraus zubekommen ob Daten im FS als geloescht markiert sind. Zusaetzlich haben vRanger und Veeam sowie wahrscheinlich andere die Moeglichkeit die Page/Swapfile vom Windows heraus zufiltern.
Gruss
Joerg
naja mir ging es nun garnichtmal um das swapfile wobei dies auch ein Nicht unteresanter Aspekt ist, im Zweifel kann ich die einfach auf ne andere vmdk legen und sichere die nicht mit, mir ging es eher um die Fragemtierung durch die Reoback Grütze, habe mich aber mit der Situation arangiert und werde mal testen die Linux Systeme auf Datei ebene einfach auf eine neue Platte zu kopieren, damit hat diese dann die "optimalen" offsets, hatte noch die alternativ Idee mir einfach mal eine Tabelle generieren zulassen welche Blöcke(danke ext 3) auf der Hdd nur eine 00 Enthalten, da ich hierbei in Sektor für Sektor Methode arbeiten muss leider "etwas" Zeitaufwendig", aber zum Glück nur einmalig.
mal schauen, hatte halt die Hoffnung ich kann den letzten Schritt irgendwie vom ESX machen lassen
möchte da ehrlich gesagt auch nicht zuviel Arbeit reinstecken, wenn man bedenkt das ich eigentlich auch Webentwickler bin und ich mich deswegen schon mit C# rumschlage :X
mal schauen, hatte halt die Hoffnung ich kann den letzten Schritt irgendwie vom ESX machen lassen
möchte da ehrlich gesagt auch nicht zuviel Arbeit reinstecken, wenn man bedenkt das ich eigentlich auch Webentwickler bin und ich mich deswegen schon mit C# rumschlage :X
-
Dayworker
- King of the Hill
- Beiträge: 13657
- Registriert: 01.10.2008, 12:54
- Wohnort: laut USV-Log am Ende der Welt...
Eine VMDK nicht mitzusichern, kann sich im Ernstfall als Bumerang beim Restore erweisen. Dann hat keiner Zeit sich um fehlende Partitionen zu kümmern.
Was ist "Reoback Grütze" und was willst du mit "optimalen offsets"?
Wozu willst du extra erst eine Tabelle generieren lassen?
Schalte CBT ab, schreibe eine Nullbits-Datei in der VM, lösche diese gleich wieder und kopiere diese im Thinformat über die "vmkfstools" direkt auf dem ESXi. Damit fehlen alle als logisch Null gekennzeichneten Sektoren in der VMDK. Alternativ kannst du nach dem CBT-Abschalten, die Nullbits-Datei samt anschließendem Löschen schreiben, das vDISK-Format beibehalten und CBT wieder einschalten. Dann landen nur noch alle wirklich geänderten Blöcke ins CBT-File.
Was ist "Reoback Grütze" und was willst du mit "optimalen offsets"?
Wozu willst du extra erst eine Tabelle generieren lassen?
Schalte CBT ab, schreibe eine Nullbits-Datei in der VM, lösche diese gleich wieder und kopiere diese im Thinformat über die "vmkfstools" direkt auf dem ESXi. Damit fehlen alle als logisch Null gekennzeichneten Sektoren in der VMDK. Alternativ kannst du nach dem CBT-Abschalten, die Nullbits-Datei samt anschließendem Löschen schreiben, das vDISK-Format beibehalten und CBT wieder einschalten. Dann landen nur noch alle wirklich geänderten Blöcke ins CBT-File.
Würde die natürlich mitsichern aber nicht ganz, sondern das was ich brauche, macht der vranger bei der windows swap denke ich nicht anders, im Restore stehen in der Datei halt nix, größe ist aber so wie sie sein soll
Auf Anweisung meines Vorgängers wurde über Reoback mit der Methode Ftp upload installiert(hat auch schon dafür gesorgt das die ein oder andere vm wegen keinen Freien Speichers nichtmehr funktionierte), stellenweise sind so 40 gb tmp files entstanden, nebenbei kämpfe ich mit error logs in selbiger größe
Optimalle Offsets sind die Speicherbereiche auf denen eben keine Tempdaten lagen sondern wirklich nur das für das Produktiv System nötige
Verstehe ich das richtig das letzte? ich deaktiviere cbt, schreibe ne dummy datei auf der vm, anschließend mach ich cbt wieder an und wenn ich eine Abfrage mache über alle benutzten Sektoren erhalte ich nur noch die die wirklich benutzt sind egal ob auf der vm mal alles benutzt war, ich die Datein durch 00 überschrieben habe?
die extra Tabelle war für den Fall das es eben nicht geht
Auf Anweisung meines Vorgängers wurde über Reoback mit der Methode Ftp upload installiert(hat auch schon dafür gesorgt das die ein oder andere vm wegen keinen Freien Speichers nichtmehr funktionierte), stellenweise sind so 40 gb tmp files entstanden, nebenbei kämpfe ich mit error logs in selbiger größe
Optimalle Offsets sind die Speicherbereiche auf denen eben keine Tempdaten lagen sondern wirklich nur das für das Produktiv System nötige
Verstehe ich das richtig das letzte? ich deaktiviere cbt, schreibe ne dummy datei auf der vm, anschließend mach ich cbt wieder an und wenn ich eine Abfrage mache über alle benutzten Sektoren erhalte ich nur noch die die wirklich benutzt sind egal ob auf der vm mal alles benutzt war, ich die Datein durch 00 überschrieben habe?
die extra Tabelle war für den Fall das es eben nicht geht
-
Dayworker
- King of the Hill
- Beiträge: 13657
- Registriert: 01.10.2008, 12:54
- Wohnort: laut USV-Log am Ende der Welt...
Die Nullbits-Datei dienst ausschließlich dazu, alle freien Sektoren mit Logisch Null zu füllen. Dazu wird der freie Bereich der VMDK mit einer Nulldatei komplett gefüllt und die Nulldatei gleich wieder gelöscht. Die VMDK enthält dann nur noch alle wirklich genutzten Sektoren und wenn man dann CBT wieder anschaltet, landen nur noch die seitdem sich veränderten Sektoren/Blöcke modulo 64KB im CBT-File.
Die maximale Anzahl freier Sektoren/Blöcke einer VMDK läßt sich immer dann beschreiben, wenn die VM über eine Live-CD gestartet wird. Die VMDK als weitere Platte einer Helfer-VM geht natürlich auch.
Das Mounten und wegschreiben muß man dann natürlich für jede VMDK bzw Partition machen. Im Anschluß CBT aktivieren nicht vergessen.
PS: Nicht irritieren lassen. Ich hab das zwar mal für das VMware-Desktopprodukt Workstation in Version 9 geschrieben. Aufgrund der Nähe der VMware-Produkte untereinander lassen sich solche Dinge aber recyceln.
Die maximale Anzahl freier Sektoren/Blöcke einer VMDK läßt sich immer dann beschreiben, wenn die VM über eine Live-CD gestartet wird. Die VMDK als weitere Platte einer Helfer-VM geht natürlich auch.
Dayworker im Thread: Shrink mit VMWare 9 möglich, wie? hat geschrieben:Ich nehm dazu immer eine Live-CD wie gparted, da Linux und Windows manchmal recht eingeschnappt auf ein komplett volles Startlaufwerk reagieren und dann zu Abstürzen neigen. Wie man mit "gparted" arbeitet, habe ich im Thread HowTo - Nachträgliches Alignment auf Sektor 2048 beschrieben. Allerdings braucht man nur die Console und nutzt die Partitionsanwendung nur zur Feststellung der Laufwerksbezeichnung. Dabei sind "sda1-4" immer Primäre und ab "sda5" werden Logische Laufwerke in den Erweiterten Partitionen bezeichnet. Wie unter Linux üblich, braucht es zum Mounten und andere Dinge "volle Rechte" (root). Einige Distros wie Suse gestatten immer noch die Anmeldung als "root", der grössere Teil nutzt jedoch aus Sicherheitsgründen inzwischen "sudo" oder "su". Für Debian basierte Distros ist "sudo" das Mittel der Wahl, um Befehle als "root" auszuführen. Hier mein Weg unter "gparted" (Debian):
- sudo mount /dev/sda1 /media (mountet die erste Partition nach /media)
- cd /media (springt in Media-Verzeichnis und somit in die dort vorher eingehängt erste Partition)
- sudo dd if=/dev/zero of=0bits bs=20971520 (beschreibt die unter "/media" eingehängte Partition mit 20MiB-Blöcken komplett voll)
- sudo rm 0bits (löscht die Datei "0bits" wieder)
- VM beenden (Rechtsklick in den Desktop und "Exit" wählen)
Das Mounten und wegschreiben muß man dann natürlich für jede VMDK bzw Partition machen. Im Anschluß CBT aktivieren nicht vergessen.
PS: Nicht irritieren lassen. Ich hab das zwar mal für das VMware-Desktopprodukt Workstation in Version 9 geschrieben. Aufgrund der Nähe der VMware-Produkte untereinander lassen sich solche Dinge aber recyceln.
naja die frage ob alle änderunge danach oder von anfang an, ich probier es mal aus, klone grad die 500 gb hdd
edit: leider nicht, siehe bild, werde ich wohl doch mit Hilfstabellen Arbeiten und in Zukunft darauf achten das so etwas nicht wieder passiert, 6h Backup Zeit für effektiv 18gb?(das ist eigentlich der Punkt der mich am meisten wurmt, Filesizemäßig wird durch gzip/zlib nicht soviel übrig bleiben) ist etwas ungünstig, trotzdem danke
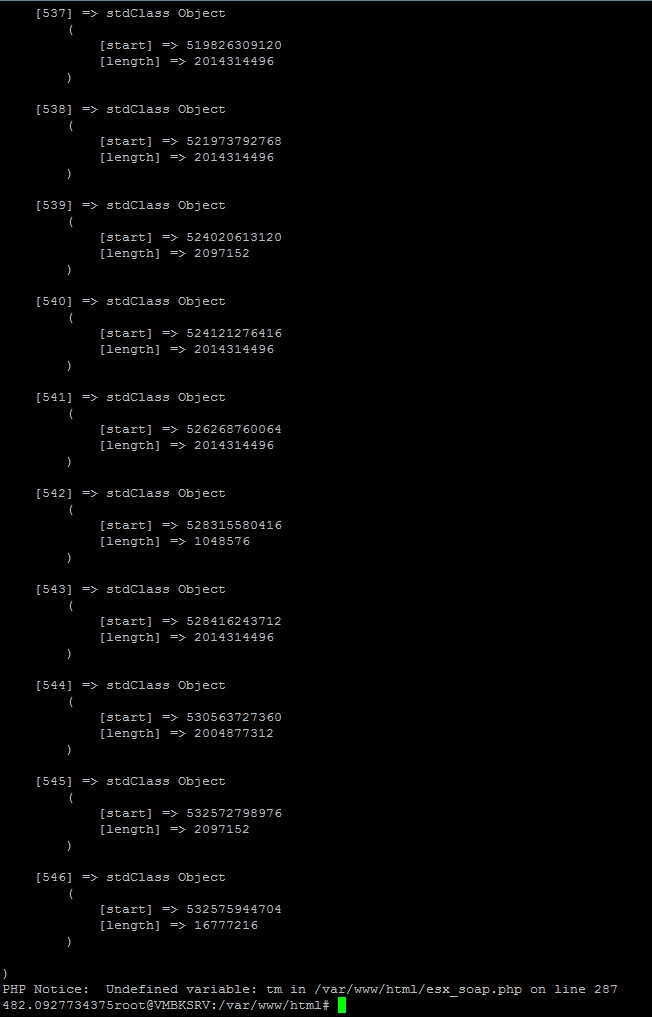
edit: leider nicht, siehe bild, werde ich wohl doch mit Hilfstabellen Arbeiten und in Zukunft darauf achten das so etwas nicht wieder passiert, 6h Backup Zeit für effektiv 18gb?(das ist eigentlich der Punkt der mich am meisten wurmt, Filesizemäßig wird durch gzip/zlib nicht soviel übrig bleiben) ist etwas ungünstig, trotzdem danke
ist eine Komplett Eigenentwicklung im Rahmen meines Prüfungsprojektes bestehend auf https://gist.github.com/scr34m/3490246 aber extrem Erweitert so das ich alles damit machen kann, dazu habe ich noch einen Wrapper geschrieben um direkt xml zuverwenden, da das bauen mit der stdclass umständlich ist(http://pastebin.com/PuygVrR5)
Zurück zu „vSphere 5.5 / ESXi 5.5“
Wer ist online?
Mitglieder in diesem Forum: 0 Mitglieder und 6 Gäste