Hallo,
gegeben sei ein Cluster aus
- 6 x ESXi 4.1 (ML 580G7, 4 x 8 Kerne, 196 GB RAM, 2 x 10 GbE iSCSI NICs, keine Jumo Frames)
- 4 x Procurve 5412nl 10 GbE iSCSI Switches (2 RZs)
- 12 x HP P4500 Lefthand (je 12x 600 SAS im RAID5, zusammen im Netzwerk RAID)
Die Latenzzeiten sind über die ESXi Hosts bei durchschnittlich 15-30 ms mit Spitzen von bis zu 200 ms. Laut VMware sollte die Latenz ja eher niedriger sein. RTT zwischen Hosts und LH Storage liegt bei ~0,200ms. Auf den Hosts laufen 20 - 40 VMs, meist W2K3 und W2K8. Die CPU und RAM Auslastung ist unkritisch.
HP hat bereits über 24 Stunden ein Performance Messung auf den Lefthands durchgeführt, dort ist die Latenz im Durchschnitt 3 ms. Switch und Lefthand Firmware ist auf dem aktuellen Stand. Ein Cluster mit einem EVA6000 SAN zeigt deutlich geringere Latenzen von unter 10 ms und das bei älterer Hardware.
Hat jemand Vergleichswerte für einen vergleichbaren Cluster, oder Tipps an welcher Stelle ich als nächstes schauen sollte?
Die Foren-SW läuft ohne erkennbare Probleme. Sollte doch etwas nicht funktionieren, bitte gerne hier jederzeit melden und wir kümmern uns zeitnah darum. Danke!
hohe Latenzzeiten mit P4500 Lefthands
Ich kann dir höchstens Vergleichswerte geben für einen iSCSI Cluster der vielleicht 1/20 von dem geschätzten 500k€ Cluster gekostet hat. Der besteht aus 2 Datacore Hosts mit 2 ESX, 2 * 1GB und läuft über 2 HP Procurve 29XX. Aber selbst da habe ich nicht so hohe Latenzen. Bei der Ausstattung muss etwas falsch konfiguriert sein. Ich habe noch keine Lefthand in der Hand gehabt, aber ich vermute die Probleme in dem Umfeld, sofern das Netzwerk ordentlich verkabelt und VLans passend konfiguriert worden sind.
Wie muss ich mir denn den Storage Cluster vorstellen aus 12 Geräten mit Netzwerkraid? Ist das dann ein großer Storagepool aus dem ich mir die LUNs schnitze?
Wie muss ich mir denn den Storage Cluster vorstellen aus 12 Geräten mit Netzwerkraid? Ist das dann ein großer Storagepool aus dem ich mir die LUNs schnitze?
-
irix
- King of the Hill
- Beiträge: 13066
- Registriert: 02.08.2008, 15:06
- Wohnort: Hannover/Wuerzburg
- Kontaktdaten:
Der Peter aus Rosenheim muesste was zu diesem Thema sagen koennen weil da muss die Lefthand sogut laufen das er Zeit hat sich mit Windows 8 zubeschaeftigen 
Der Georg hat auch einen Lefthand Multi SiteCluster seit laengerem im Einsatz.
Also auf einem Host mit 34 aktiven VMs welcher per 2x10GbE am SAN haengt zeigt die vSphere eigene "Datastore" 24h Statistik als max. Latenz 7ms. Allerdings kein Lefthand und auch nur "lokal" das heist ohne Replikation.
Gruss
Joerg
Der Georg hat auch einen Lefthand Multi SiteCluster seit laengerem im Einsatz.
Also auf einem Host mit 34 aktiven VMs welcher per 2x10GbE am SAN haengt zeigt die vSphere eigene "Datastore" 24h Statistik als max. Latenz 7ms. Allerdings kein Lefthand und auch nur "lokal" das heist ohne Replikation.
Gruss
Joerg
JMcClane hat geschrieben:Wie muss ich mir denn den Storage Cluster vorstellen aus 12 Geräten mit Netzwerkraid? Ist das dann ein großer Storagepool aus dem ich mir die LUNs schnitze?
Im Endeffekt ja. Man sieht im Cluster Manager der Lefthands den Speicher und erzeugt daraus dann die LUNs. Die sind bei uns 2 TB groß. In Wirklichkeit werden dann aber 4 TB belegt, weil die Lefthand ja ein RAID1 zwischen den beiden RZs machten Die RZs sind 500m entfernt und es sind Singlemode Fasern verlegt (an der Stelle gab es mal Problem, die sind aber behoben).
Der Support hat sich das auch alles schon mal angeschaut, aber ist auch zu keinem Schluss bisher gekommen.
Edit:
Ich muss noch dazu sagen, dass die Performance Charts für die _Datastores_ durchaus Latenzen von nur 5 - 10 ms im Durchschnitt anzeigen. Die Disk Charts liegen bei 20 - 30 ms. Mit esxtop habe ich auch Werte von > 15 ms gesehen.
Ist das ein echtes Multisite Cluster oder habt ihr ein Standard-Cluster auseinandergezogen (auch das geht...)??
Wie sieht es mit VLANs, MSTP/ RSTP, Flow-Control aus? Ich könnte mir evtl. etwas in RIchtung Queue Depth vorstellen. Hast du mal beobachtet wie viele IOs in der Queue sind? Gibt es eine positive Korrelation zwischen Latency und IOPS, also hohe Latency bei vielen IOPS?
Wie sieht es mit VLANs, MSTP/ RSTP, Flow-Control aus? Ich könnte mir evtl. etwas in RIchtung Queue Depth vorstellen. Hast du mal beobachtet wie viele IOs in der Queue sind? Gibt es eine positive Korrelation zwischen Latency und IOPS, also hohe Latency bei vielen IOPS?
Was verstehst du unter "echtes Multisite Cluster"? Die LHs sind auf 2 Lokationen verteilt, es steht insg. die Hälfte des Speichers zu Verfügung und der Cluster Manager / Fail Over Manager regelt das Quorum.
Flow Control auf den Switch Ports der Lefthands ist aktiv, außerdem bei den ESX Hosts wo es geht. Die Qlogic NICs bieten mit dem aktuellen Treiber keine Möglichkeit Flow Control zu aktivieren, bei den Emulex Karten ist es aktiv. Auf den Trunk Ports zwischen den Switches ist es deaktiviert. Das iSCSI Netz ist vom restlichen Netz komplett getrennt, VLANs werden dort AFAIK nicht verwendet. Zu STP muss ich schauen, aktiv ist es natürlich, es wurde auch im Rahmen des Projekts vom Lieferanten eingerichtet.
Ich werde am Mo. einige Graphen verlinken. Was ist an der Stelle die richtige Chart, die Disk oder Datastore? Bin neu in dem Projekt, bisher wird immer auf die Graphen der Disk Performance Chart Bezug genommen.
Flow Control auf den Switch Ports der Lefthands ist aktiv, außerdem bei den ESX Hosts wo es geht. Die Qlogic NICs bieten mit dem aktuellen Treiber keine Möglichkeit Flow Control zu aktivieren, bei den Emulex Karten ist es aktiv. Auf den Trunk Ports zwischen den Switches ist es deaktiviert. Das iSCSI Netz ist vom restlichen Netz komplett getrennt, VLANs werden dort AFAIK nicht verwendet. Zu STP muss ich schauen, aktiv ist es natürlich, es wurde auch im Rahmen des Projekts vom Lieferanten eingerichtet.
Ich werde am Mo. einige Graphen verlinken. Was ist an der Stelle die richtige Chart, die Disk oder Datastore? Bin neu in dem Projekt, bisher wird immer auf die Graphen der Disk Performance Chart Bezug genommen.
bla!zilla hat geschrieben:Es gibt Standard- und Multisite Cluster bei der P4000. Man kann auch ein Standard-Cluster auf zwei RZs verteilen, in dem man die Reihenfolge, in der man die Nodes ins Cluster hebt, beachtet.
Ich habe mich mit dem Unterschied noch nicht tief gehend beschäftigt, aber im "Running VMware vSphere 4 on HP LeftHand P4000 SAN Solutions" finde ich dazu folgendes:
Code: Alles auswählen
HP P4000 Multi-Site SANs and vSphere 4
HP P4000 Multi-Site SANs enable vSphere 4 clusters to be stretched across locations to provide multi-site VMotion, HA (High Availability), DRS (Distributed Resource Scheduler), and FT. Multi-Site SAN configurations use synchronous replication in the underlying SAN to create a single SAN that spans both location. This allows vSphere 4 clusters to act exactly the same way they do when physically located in a single location. When connecting ESX or ESXi hosts to a Multi-Site SAN each of the virtual IP addresses (VIPs) of the SAN from each site should be listed in the discovery list of the ESX or ESXi software initiator. Path selection policy for Multi-Site SAN volumes should be set to fixed (default).
Das klingt für mich nach stretched cluster. Wir haben ein Subnetz in dem sich alle Interfaces befinden.
bla!zilla hat geschrieben:Das klingt für mich nach stretched cluster. Wir haben ein Subnetz in dem sich alle Interfaces befinden.
Kann, muss nicht. Schau bitte in die CMC. Wenn du auf das Cluster klickst kannst du auf der rechten Seite unter "Details" den Clustertyp sehen.
Es ist ein Multi-Site Cluster. Aus dem HP Dokument sticht der Unterschied für mich nicht so recht hervor.
Ich habe mal 4 Graphen hochgeladen.
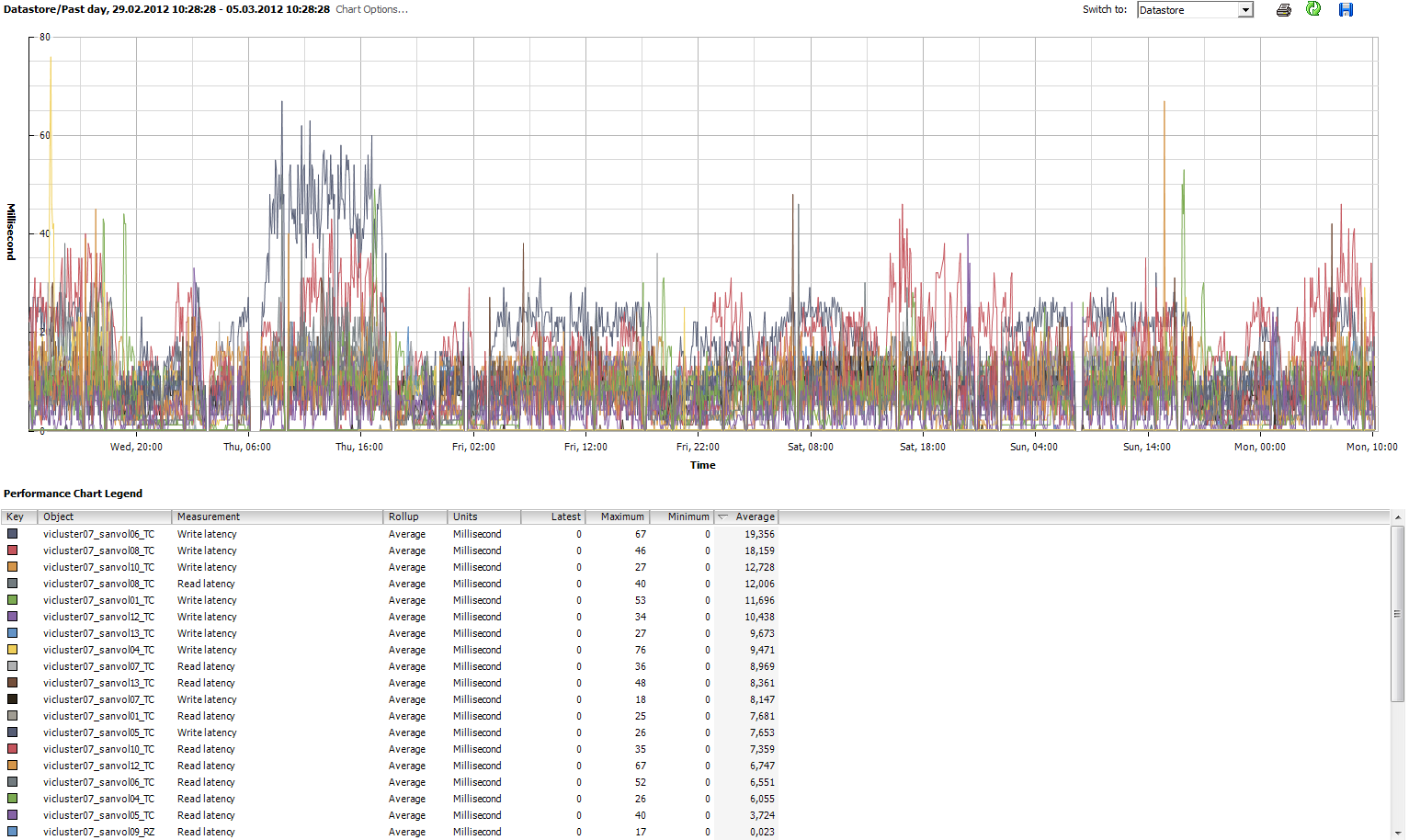
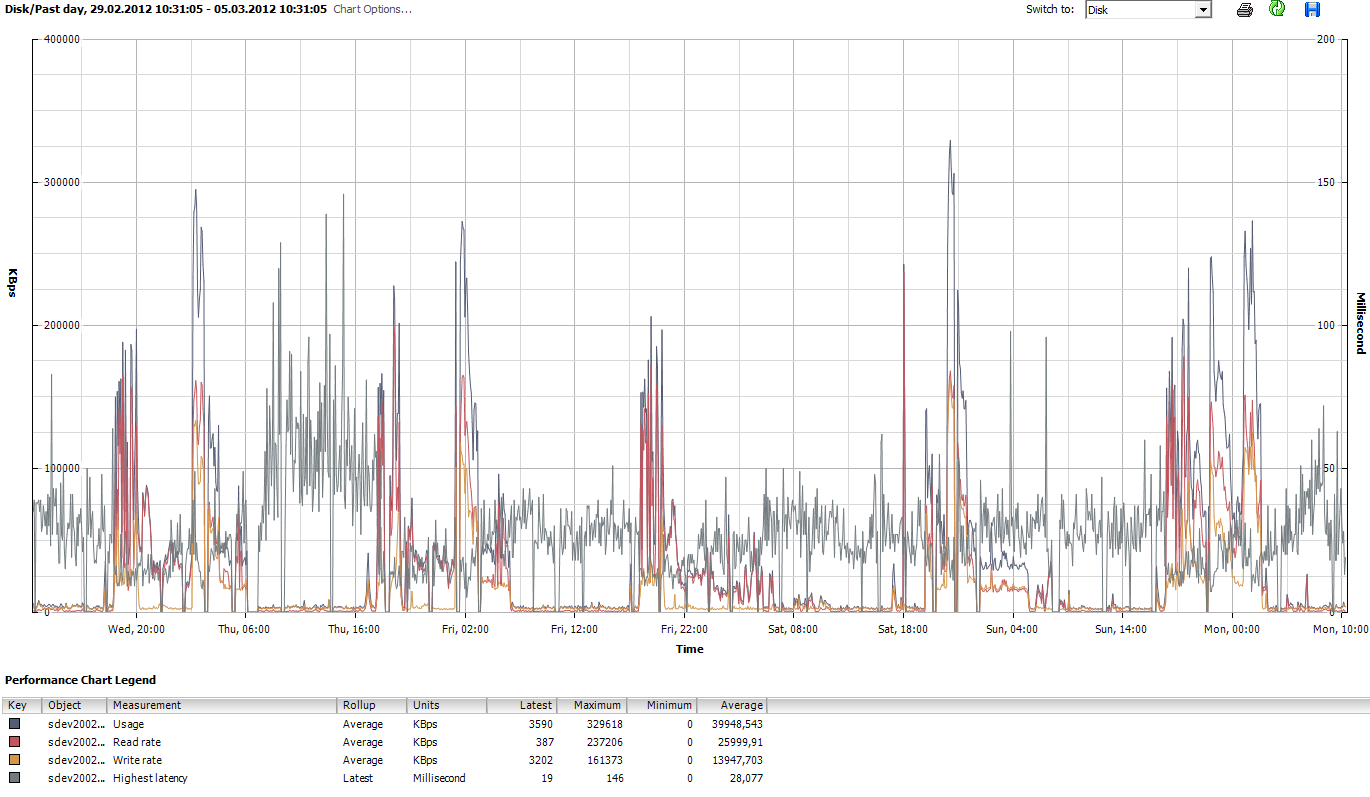
Die ersten zwei Graphen sind von einem Host der an einem FC SAN mit EVA hängt (DL380G6, 98 GB RAM, 26 laufende VMs).
http://www.abload.de/img/eva_host34_datastorelfccz.png
http://www.abload.de/img/eva_host34_diskggfm8.png
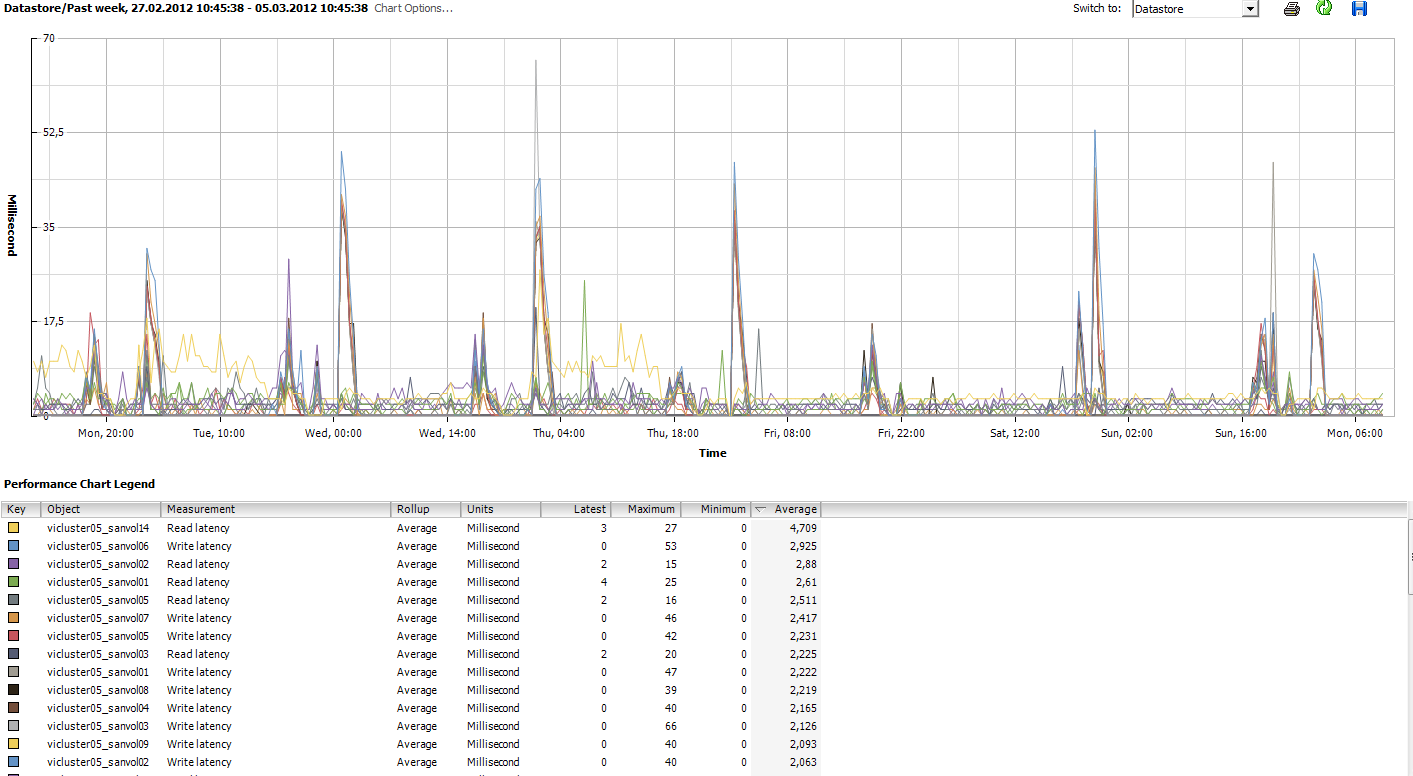
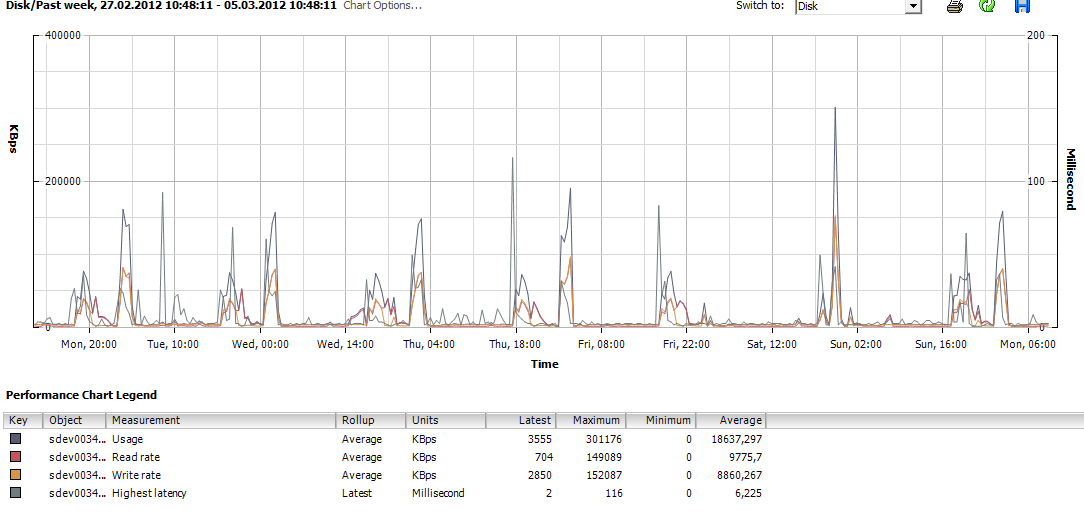
Die nächsten Graphen zeigen einen Host der an der iSCSI Lefthand hängt (DL580G7, 196 GB RAM, 38 laufende VMs).
http://www.abload.de/img/lefthand_host02_datascefkq.png
http://www.abload.de/img/lefthand_host02_disk0pfa1.png
Die LUNs/Datastores auf der EVA wurden noch mit 1 TB Größe angelegt, auf der Lefthand mit 2 TB.
Ich bin mir immer noch nicht sicher, ob es wirklich ein Performance Problem gibt. Die EVA Farm wird immer als Vergeich hergenommen. Da ich erst seit kurzem involviert bin, fehlt mir etwas die Vorgeschichte.
Die ersten zwei Graphen sind von einem Host der an einem FC SAN mit EVA hängt (DL380G6, 98 GB RAM, 26 laufende VMs).
http://www.abload.de/img/eva_host34_datastorelfccz.png
{kind=link}
http://www.abload.de/img/eva_host34_diskggfm8.png
{kind=link}
Die nächsten Graphen zeigen einen Host der an der iSCSI Lefthand hängt (DL580G7, 196 GB RAM, 38 laufende VMs).
http://www.abload.de/img/lefthand_host02_datascefkq.png
{kind=link}
http://www.abload.de/img/lefthand_host02_disk0pfa1.png
{kind=link}
Die LUNs/Datastores auf der EVA wurden noch mit 1 TB Größe angelegt, auf der Lefthand mit 2 TB.
Ich bin mir immer noch nicht sicher, ob es wirklich ein Performance Problem gibt. Die EVA Farm wird immer als Vergeich hergenommen. Da ich erst seit kurzem involviert bin, fehlt mir etwas die Vorgeschichte.
bla!zilla hat geschrieben:Also auf den ersten Blick ist alles okay. Die hohen Latenzen treten bei hohem IO auf. Zudem geht durch die P4000 deutlich mehr durch, als durch die EVA - die lümmelt ja quasi nur rum.
So auf den ersten Blick sehe ich keine Dinge, die mich beunruhigen würden.
Sehe ich eigentlich ähnlich. Auf den 2 TB Datastores der LHs liegen auch deutlich mehr VMs als eigentlich empfohlen werden. Es gibt dort kaum ein DS das weniger als 15 VMs hat.
In dem Bereich (locking) gab es doch in vSphere 5 auch Verbesserungen, vlt. ein guter Grund demnächst von 4.1 weg zu gehen.
-
irix
- King of the Hill
- Beiträge: 13066
- Registriert: 02.08.2008, 15:06
- Wohnort: Hannover/Wuerzburg
- Kontaktdaten:
pirx hat geschrieben:bla!zilla hat geschrieben:Also auf den ersten Blick ist alles okay. Die hohen Latenzen treten bei hohem IO auf. Zudem geht durch die P4000 deutlich mehr durch, als durch die EVA - die lümmelt ja quasi nur rum.
So auf den ersten Blick sehe ich keine Dinge, die mich beunruhigen würden.
Sehe ich eigentlich ähnlich. Auf den 2 TB Datastores der LHs liegen auch deutlich mehr VMs als eigentlich empfohlen werden. Es gibt dort kaum ein DS das weniger als 15 VMs hat.
In dem Bereich (locking) gab es doch in vSphere 5 auch Verbesserungen, vlt. ein guter Grund demnächst von 4.1 weg zu gehen.
Also das die EVA eigentlich weniger tut ist mir anhand der Graphen auch aufgefallen. Hinzu kommt das ich Glaube ihr sucht Probleme wo garkeine sind
Wenn ich die Aussage mit "Empfehlung von Anzahl VMs pro Datastore" hoere dann geht mir gleich schon das Klappmesser in der Hose auf. Hier sind deutlich mehr VMs auf einen Datastore... und der Hoechstand waren mal 53. Ich stelle es Ausserfrage das man es Verteilen sollte.... aber dazu muss man das Verhalten der VM kennen.
Ich glaube du wolltest SCSI Reserveration ansprechen mit dem Locking.... wenn ihr keine lfd. Snaps habt bzw. Thinprovisioning auf VMware Ebene einsetzt dann ist das alles kein Thema. Ja es gab Verbesserungen und ja es gibt auch VAAI und "Hardware Assisted Locking".
Gruss
Joerg
-
Nukite2007
- Member
- Beiträge: 356
- Registriert: 16.05.2007, 11:48
- Wohnort: Rosenheim / Obb.
hallo @all
habe jetzt mal bei uns wegen den Latenzzeiten nachgesehen..
Wir haben ja die Lefthand vor nicht all zu langer Zeit in Betrieb genommen.
http://s1.directupload.net/file/d/2820/a3wvj9b5_jpg.htm
VG
Peter
habe jetzt mal bei uns wegen den Latenzzeiten nachgesehen..
Wir haben ja die Lefthand vor nicht all zu langer Zeit in Betrieb genommen.
http://s1.directupload.net/file/d/2820/a3wvj9b5_jpg.htm
VG
Peter
Hier noch ein Graph von einem Host, bei dem es größere Ausrutscher bei den LH Datastores gibt. Teilweise bis zu 500 ms und beim sanvol13 und einigen anderen DS für einige Minuten > 50 ms.
http://www.abload.de/img/lefthand_host06_datasr7f6z.png
http://www.abload.de/img/lefthand_host06_datasr7f6z.png
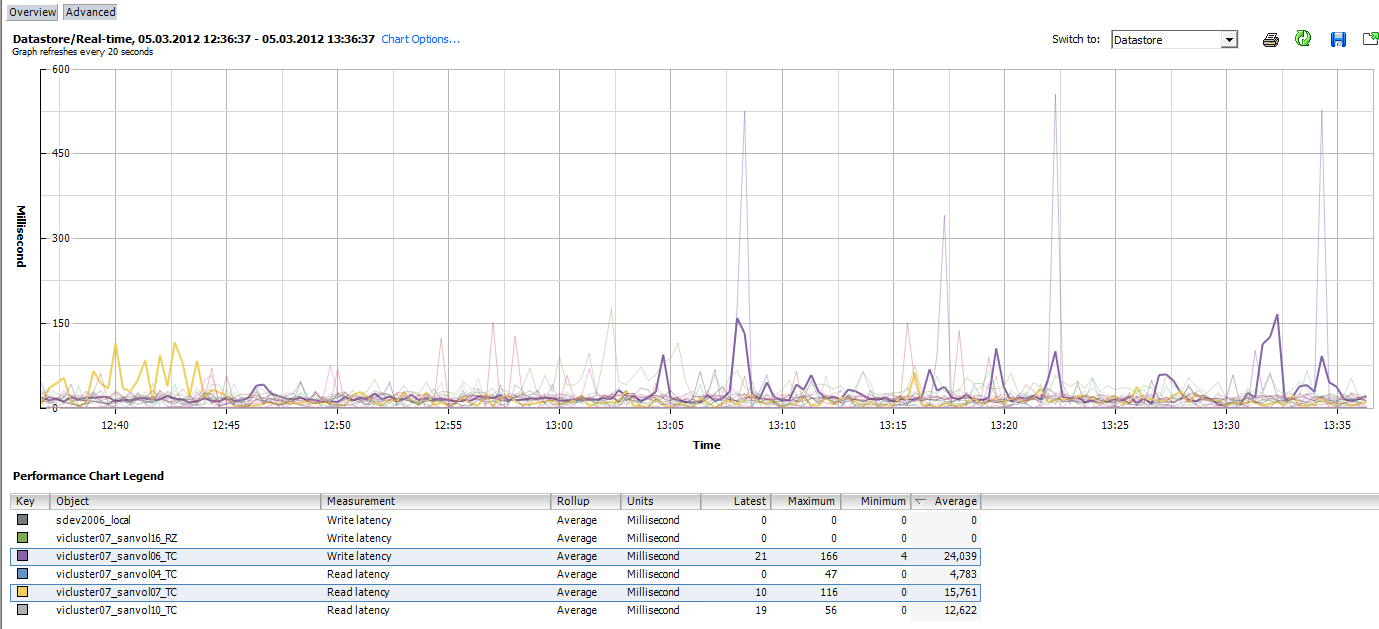{kind=link}
Ich versuche gerade noch die Latenzen an verschiedenen Stellen zu messen. Den Performance Monitor der Lefthand CMC finde ich nicht so gelungen. Dort sehe ich aber folgendes für eine LUN:
IO Latency Reads: avg. 11,3 ms
IO Latency Writes: avg. 5,0 ms
Im vCenter sehe ich für das Datastore das auf der LUN liegt
Read latency: avg. 15,1 ms
Write latency: avg. 19,5 ms
Vor allem den großen Unterschied bei Write IOs kann ich mir nicht erklären. Woher kommen die Unterschiede? iSCSI Switches, ESXi NICs, VMFS? Überhaupt sehen die Graphen im Performance Monitor der Lefthand anders aus als die im vCenter. Spikes oder Perioden mit höherer Latenz fehlen teilweise in einem der Graphen.
IO Latency Reads: avg. 11,3 ms
IO Latency Writes: avg. 5,0 ms
Im vCenter sehe ich für das Datastore das auf der LUN liegt
Read latency: avg. 15,1 ms
Write latency: avg. 19,5 ms
Vor allem den großen Unterschied bei Write IOs kann ich mir nicht erklären. Woher kommen die Unterschiede? iSCSI Switches, ESXi NICs, VMFS? Überhaupt sehen die Graphen im Performance Monitor der Lefthand anders aus als die im vCenter. Spikes oder Perioden mit höherer Latenz fehlen teilweise in einem der Graphen.
Wer ist online?
Mitglieder in diesem Forum: 0 Mitglieder und 5 Gäste