Die Foren-SW läuft ohne erkennbare Probleme. Sollte doch etwas nicht funktionieren, bitte gerne hier jederzeit melden und wir kümmern uns zeitnah darum. Danke!
Konfiguration P2000 G3
-
mbreidenbach
- Experte
- Beiträge: 1006
- Registriert: 30.10.2004, 12:41
ProCurve... da wrden Jumbo Frames per VLAN eingeschaltet glaube ich mich dumpf zu entsinnen
Ob Jumbos funktionieren kann man mit vmkping testen.. da gibts ne option für nicht fragmentieren dann gehen die nicht durch wenn jumbo frames nicht klappen
ahja http://kb.vmware.com/kb/1003681
Ob Jumbos funktionieren kann man mit vmkping testen.. da gibts ne option für nicht fragmentieren dann gehen die nicht durch wenn jumbo frames nicht klappen
ahja http://kb.vmware.com/kb/1003681
mbreidenbach hat geschrieben:ProCurve... da wrden Jumbo Frames per VLAN eingeschaltet glaube ich mich dumpf zu entsinnen
Ob Jumbos funktionieren kann man mit vmkping testen.. da gibts ne option für nicht fragmentieren dann gehen die nicht durch wenn jumbo frames nicht klappen
ahja http://kb.vmware.com/kb/1003681
also mit MTU 9000 geht garnichts durch. Wenn ich den Header abziehe (also MTU 8784) habe ich ne Response-Time von 1.466/1.482/1.497 ms. Kommt mir ziehmlich hoch vor.
Unser Thecus hat mit den gleichen Einstellungen 0.584/0.648/0.739 ms ... wobei ich da auch mit einer MTU von 9000 pingen kann und in etwa die gleiche response time habe!
Aso und ja, die JumboFrames werden auf den ProCurves pro VLAN aktiviert.

continuum hat geschrieben:stell die jumbo frames ab - einen Performancevorteil davon hast du eh nicht - dagegen aber massive Probleme wenn auch nur ein Geraet eine andere MTU verwendet.
Jumboframes moegen gut laufen wenn du alle beteiligten Geraete vom selben Vendor hast - sonst aber eher nicht
Server = HP
Switch = HP
Storage = HP
Config war überall richtig. Nur scheint das P2000-Array Probleme mit MTU 9000 zu haben. Ich hab jetzt überall wieder Jumbo deaktiviert und MTU 1500 eingestellt. Die Latenz-Probleme sind weg. 2 Jahre lief die Config einwnadfrei mit der gleichen Hardware und das NAS war von Thecus. Jetzt kommt ein weiteres HP NAS dazu und es gibt Probleme. Ich denke das Problem liegt darin, dass man dem P2000 keine MTU mitgeben kann. Man hat dort nur die Möglichkeit Jumbo zu aktivieren bzw. zu deaktivieren.
Wie gesagt die Latenz-Fehler bzw. Verbindungsabbrüche sind weg. Zum Thema Performance kann ich aktuell noch keine Aussage tätigen.
Hiho,
habe nun vom HP-Support die Anweisung bekommen VAAI zu deaktivieren und die komplette Config wieder auf MTU 9000 zu stellen.
Gesagt getan. Nun hab war die Config wie folgt:
MTU 9000 + FlowControl = alle Targets weg und auf dem Switch Meldungen ala:
Also FC wieder aus... immernoch alle Targets weg. Auf der P2000 ist außerdem nach jeder Umstellung der Netzwerkconfig Port B2 als Disconnected makiert.
Wenn ich dann am Switch den Port deaktivere und wieder aktiviere kommt der Link zurück.
Nachdem ich nun die MTU wieder auf 1500 habe und etliche Male die HBAs neu abgesucht habe, sind die iSCSI-Targets wieder gekommen.
Ich bin ratlos. Vom HP-Support kommen nur komische Vorschläge, die eher nach "rumprobieren" klingen.
Kann es vielleicht doch am Switch liegen? Oder evtl. die Firmware der Netzwerkkarten?
habe nun vom HP-Support die Anweisung bekommen VAAI zu deaktivieren und die komplette Config wieder auf MTU 9000 zu stellen.
Gesagt getan. Nun hab war die Config wie folgt:
MTU 9000 + FlowControl = alle Targets weg und auf dem Switch Meldungen ala:
Flow control Jumbo frames fault on port 35 Description:
"Flow control and jumbo frames fault was detected on port 35. Port 35 Flow control and jumbo frames should not be enabled concurrently on the same port. Flow control may not function correctly due to higher consumption of packet buffers for jumbo frames. "
Also FC wieder aus... immernoch alle Targets weg. Auf der P2000 ist außerdem nach jeder Umstellung der Netzwerkconfig Port B2 als Disconnected makiert.
Wenn ich dann am Switch den Port deaktivere und wieder aktiviere kommt der Link zurück.
Nachdem ich nun die MTU wieder auf 1500 habe und etliche Male die HBAs neu abgesucht habe, sind die iSCSI-Targets wieder gekommen.
Ich bin ratlos. Vom HP-Support kommen nur komische Vorschläge, die eher nach "rumprobieren" klingen.
Kann es vielleicht doch am Switch liegen? Oder evtl. die Firmware der Netzwerkkarten?
Ich dachte die ProCurve 2848 können MTU 9000.
Aber egal. Hab gerade nochmal FlowControl aktiviert. Wieder Port B2 von der P2000 down. MTU stand auf 1500 überall.
Auf den ESXi sind die Targets wieder weg und ich erhalte diese Meldung im vmkernel.log:
Aber egal. Hab gerade nochmal FlowControl aktiviert. Wieder Port B2 von der P2000 down. MTU stand auf 1500 überall.
Auf den ESXi sind die Targets wieder weg und ich erhalte diese Meldung im vmkernel.log:
2012-01-29T19:15:42.519Z cpu6:9886)WARNING: NMP: nmp_DeviceStartLoop:721:NMP Device "naa.600c0ff0001302cd1ff1114f01000000" is blocked. Not starting I/O from device.
2012-01-29T19:15:43.519Z cpu6:9856)WARNING: vmw_psp_rr: psp_rrSelectPathToActivate:972:Could not select path for device "naa.600c0ff0001302cd1ff1114f01000000".
2012-01-29T19:15:43.519Z cpu2:2665)WARNING: NMP: nmpDeviceAttemptFailover:599:Retry world failover device "naa.600c0ff0001302cd1ff1114f01000000" - issuing command 0x412400739780
2012-01-29T19:15:43.519Z cpu2:2665)WARNING: vmw_psp_rr: psp_rrSelectPath:1146:Could not select path for device "naa.600c0ff0001302cd1ff1114f01000000".
2012-01-29T19:15:43.519Z cpu2:2665)WARNING: NMP: nmpDeviceAttemptFailover:658:Retry world failover device "naa.600c0ff0001302cd1ff1114f01000000" - failed to issue command due to Not found (APD), try again...
2012-01-29T19:15:43.519Z cpu2:2665)WARNING: NMP: nmpDeviceAttemptFailover:708:Logical device "naa.600c0ff0001302cd1ff1114f01000000": awaiting fast path state update...
2012-01-29T19:15:44.519Z cpu6:9857)WARNING: vmw_psp_rr: psp_rrSelectPathToActivate:972:Could not select path for device "naa.600c0ff0001302cd1ff1114f01000000".
2012-01-29T19:15:44.519Z cpu6:9886)WARNING: NMP: nmpDeviceAttemptFailover:599:Retry world failover device "naa.600c0ff0001302cd1ff1114f01000000" - issuing command 0x412400739780
2012-01-29T19:15:44.519Z cpu6:9886)WARNING: vmw_psp_rr: psp_rrSelectPath:1146:Could not select path for device "naa.600c0ff0001302cd1ff1114f01000000".
2012-01-29T19:15:44.519Z cpu6:9886)WARNING: NMP: nmpDeviceAttemptFailover:658:Retry world failover device "naa.600c0ff0001302cd1ff1114f01000000" - failed to issue command due to Not found (APD), try again...
2012-01-29T19:15:44.519Z cpu6:9886)WARNING: NMP: nmpDeviceAttemptFailover:708:Logical device "naa.600c0ff0001302cd1ff1114f01000000": awaiting fast path state update...
Na zumindest zu der FM failed to issue command due to Not found (APD) gibt es doch genug hinweise.
Welche Vsphere Version läuft den auf den ESXi?
z.B. http://kb.vmware.com/selfservice/micros ... Id=2000835
Welche Vsphere Version läuft den auf den ESXi?
z.B. http://kb.vmware.com/selfservice/micros ... Id=2000835
Sind alles ESXi 5... Ja auf der Seite war ich schon. 1 Host konnte ich nun garnicht mehr herunterfahren nicht mal n force reboot ging. Musste über iLO Hardcore ausschalten.
Nun sind von keinem der Esxi mehr Targets erreichbar. Komme auch mit nem vmkping nicht mehr durch. Werd mal versuchen das NAS neuzustarten....
Nun sind von keinem der Esxi mehr Targets erreichbar. Komme auch mit nem vmkping nicht mehr durch. Werd mal versuchen das NAS neuzustarten....
war alles aktiv. hab nun alles durchgestartet und meine ziele vorerst wieder. Ich hab keine Ahnung was da los ist. Leider is das Ganze keine Testumgebung sondern Produktiv. Die Targets sind wieder gekommen, nachdem ich auf dem Switch die Ports wo die ESXi dranhängen de- und wieder aktiviert habe.
Hab die Config 1:1 so wie auf Seite 1. 2 VLANs 2 Subnetze... und das Port B2 immer wieder aussteigt ist denke ich auch nicht normal.
Jetzt brauch ich erstmal n Baldrian-Tee... Wenn die VMs jetzt noch hochkommen brauch ich mich nicht erschießen.
Hab die Config 1:1 so wie auf Seite 1. 2 VLANs 2 Subnetze... und das Port B2 immer wieder aussteigt ist denke ich auch nicht normal.
Jetzt brauch ich erstmal n Baldrian-Tee... Wenn die VMs jetzt noch hochkommen brauch ich mich nicht erschießen.
Ich habe gerade folgendes festgestellt:
Wenn ich den Uplink iSCSI-1 VLAN 200 entferne läuft vmkping über iSCSI-2 VLAN 300. Wenn ich dann den Link wieder stecke ist es genau andersrum. Es ist also immer nur die zuletzt gesteckte Verbindung aktiv - klingt böse nach Spanning Tree. Was aber eigentlich nicht sein kann, da die beiden Uplinks ja in verschiedenen VLANs sind.
Spanning Tree ist übrigends auf dem Switch aus.
Wenn ich den Uplink iSCSI-1 VLAN 200 entferne läuft vmkping über iSCSI-2 VLAN 300. Wenn ich dann den Link wieder stecke ist es genau andersrum. Es ist also immer nur die zuletzt gesteckte Verbindung aktiv - klingt böse nach Spanning Tree. Was aber eigentlich nicht sein kann, da die beiden Uplinks ja in verschiedenen VLANs sind.
Spanning Tree ist übrigends auf dem Switch aus.
bla!zilla hat geschrieben:Poste bitte mal ein show running-config vom Switch.
Hier:
; J4904A Configuration Editor; Created on release #I.10.77
interface 17
no lacp
exit
interface 18
no lacp
exit
interface 19
no lacp
exit
interface 20
no lacp
exit
interface 21
no lacp
exit
interface 22
no lacp
exit
interface 23
no lacp
exit
interface 24
no lacp
exit
interface 25
no lacp
exit
interface 26
no lacp
exit
interface 27
no lacp
exit
interface 28
no lacp
exit
trunk 17-20 Trk1 Trunk
trunk 21-24 Trk2 Trunk
trunk 25-28 Trk3 Trunk
ip default-gateway 192.168.100.8
snmp-server community "public" Unrestricted
vlan 1
name "DEFAULT_VLAN"
forbid 35-42,44
untagged 1-11,43,45-48,Trk1-Trk3
ip address 192.168.100.14 255.255.255.0
no untagged 12-16,29-42,44
exit
vlan 200
name "iSCSI-1"
untagged 12-16,34
tagged 36-37,39-41,44
exit
vlan 300
name "iSCSI-2"
untagged 29-33
tagged 35,38,42
exit
fault-finder bad-driver sensitivity high
fault-finder bad-transceiver sensitivity high
fault-finder bad-cable sensitivity high
fault-finder too-long-cable sensitivity high
fault-finder over-bandwidth sensitivity high
fault-finder broadcast-storm sensitivity high
fault-finder loss-of-link sensitivity high
fault-finder duplex-mismatch-HDx sensitivity high
fault-finder duplex-mismatch-FDx sensitivity high
spanning-tree Trk1 priority 4
spanning-tree Trk2 priority 4
spanning-tree Trk3 priority 4
password manager
bla!zilla hat geschrieben:Also in den iSCSI VLANs sind keine Jumbo Frames aktiviert. An welchen Ports hängt die MSA?
Jop ich hab gestern alles zurückgestellt, da garnichts mehr ging und die VMs alle auf der MSA liegen.
Die MSA hängt mit
A1 A3 B1 B3 an den Ports: 13 14 15 16
A2 A4 B2 B4 an den Ports: 29 30 31 32
Esxi 1 = 41 42
Esxi 2 = 37 38
Esxi 3 = 35 36
Thecus A1 34 B1 33


Ist es normal, dass die MSA sich selbst auch als Host aufführt?
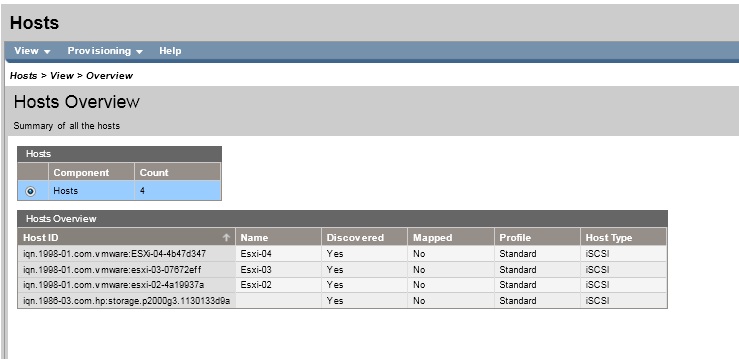
Außerdem bekomme ich auf dem Switch die Meldung:
Auf genau dem Port der in der Netzwerk-Config weiter oben zu sehen ist!

Außerdem bekomme ich auf dem Switch die Meldung:
A device on port 41 is transmitting packets shorter than 64 bytes or longer than 1518 bytes (longer than 1522 bytes if tagged), with valid CRCs.
Auf genau dem Port der in der Netzwerk-Config weiter oben zu sehen ist!
UrsDerBär hat geschrieben:Ganz schön mutig alles an einen Switch zu hängen... Was wenn der abkackt oder du fehler konfigurierst? Dann schiesst du die komplette Umgebung ab. Dann fast lieber gar keinen Switch (sofern supported).
Grüsse und so
Auf Grund des Aufbaus gehts leider nur "unschön" direkt. Klar hat es Nachteile... aber noch n Switch aus Gründen der Redundanz ist aktuell nicht drin. Wir haben noch mehr dieser Serie und n nächtliches Backup-Scipt für die ProCurves (nein die confs liegen nicht im iSCSI) ... von daher könnte man dann schnell nen anderen rausreißen und die Config draufspielen.
Nun zum Thema:
Dass das MSA sich selbst als Host anzeigt ist laut Aussage des HP-Supports absolut nicht normal. Er meinte das könne auf Grund eines "misconfigured cabeling" sein. Ein Neustart der kompletten MSA würde da wohl abhilfe schaffen. Nach 3 Std. Remote-Session und verschiedener Tests konnte mir der HP-Support bei dem eigentichen Problem nicht helfen.
Ich habe aber gestern den VMWare Support zusätzlich kontaktiert, da ja die Hosts diejenigen sind, die die Verbindung verlieren. Der erste hat sich gestern 1 Std. nach öffnen des Case remote eingeklinkt und nach 3 Minuten gemeint, dass der Fall nix für ihn ist. Das müsse sich n Storage Senior anschauen. Der hat sich kurz vor 19 Uhr gemeldet, mit der Bitte um Logdateien. Dann mussten 350 MB Logs auf deren Server gepackt werden (vspehre und vcenter nicht mit drin).Bis eben nix gehört. Nun kam ne Mail, wo drin stand, was ich alles ändern soll. Sind ingesamt 12 verschiedene Dinge die ich ändern und abchecken soll. Er sei sich sicher, dass nach den Änderungen alles läuft.
Ein Part weckt Hoffnungen:
die iSCSI Konfiguration hat einen bekannten Fehler
# aendern Sie das vSwitch Design
# 2 vSwitches fuer iSCSI, je ein vmkernel Port, je eine physische NIC
# das Problem ist VMware Engineering bekannt (Pfade koennen unbegruendet ausfallen) und wird mit Update 1 (Maerz) gefixt
Ich hoffe, dass das genau der Fehler für unsere Pfadausfälle ist... wusste garnicht, dass U1 im März schon kommt
Grüße
Alex
Wer ist online?
Mitglieder in diesem Forum: 0 Mitglieder und 5 Gäste